代码部署:
服务器python环境Speech,代码目录/home/inspur/bl/STT
|
1 2 3 |
conda create -n Speech python=3.9 conda activate Speech |
Faster whisper
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 安装whisper https://github.com/openai/whisper pip install -U openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple # 安装ffmpeg windows使用choco,centos使用https://blog.csdn.net/SE_JW/article/details/130708445 choco install ffmpeg # 安装setuptools-rust pip install setuptools-rust -i https://pypi.tuna.tsinghua.edu.cn/simple # 安装faster-whisper https://github.com/SYSTRAN/faster-whisper pip install faster-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple # 下载模型至本地目录 https://huggingface.co/Systran/faster-whisper-large-v3/tree/main https://huggingface.co/openai/whisper-large-v3/tree/main # data目录下的语音数据示例可以从下面网站下载 https://www.voiceover-samples.com/languages/chinese-voiceover/ # 运行fasterwhisper_demo.py测试 # 备注:windows测试,遇见报错RuntimeError: Library cublas64_12.dll is not found or cannot be loaded # 将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\bin目录下的 # cublas64_11.dll复制为cublas64_12.dll解决。(https://github.com/SYSTRAN/faster-whisper/issues/535) |
faster-whisper基于whisper,拥有更快的推理速度。
目前测试来看medium和large-v3模型相对准确,20s语音推理速度1.8s。
FunASR
开源模型:
https://www.modelscope.cn/models?page=1&tasks=auto-speech-recognition
服务器/home/inspur/bl/STT/funasr
本地flask或者Fastapi部署测试,安装如下环境
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# https://github.com/alibaba-damo-academy/FunASR/blob/main/README_zh.md pip install -U funasr -i https://pypi.tuna.tsinghua.edu.cn/simple pip install -U modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple pip install torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple pip install hdbscan -i https://pypi.tuna.tsinghua.edu.cn/simple pip install fastapi -i https://pypi.tuna.tsinghua.edu.cn/simple pip install uvicorn -i https://pypi.tuna.tsinghua.edu.cn/simple pip install funasr_onnx -i https://pypi.tuna.tsinghua.edu.cn/simple # fastapi mutipart格式 pip install pydub -i https://pypi.tuna.tsinghua.edu.cn/simple pip install python-multipart -i https://pypi.tuna.tsinghua.edu.cn/simple pip install websockets -i https://pypi.tuna.tsinghua.edu.cn/simple conda install pyaudio |
Docker服务端部署与客户端测试文档:
Docker部署无需安装环境
实时版本
https://github.com/alibaba-damo-academy/FunASR/blob/main/runtime/docs/SDK_advanced_guide_online_zh.md
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 启动镜像 sudo docker pull \ registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.9 mkdir -p ./funasr-runtime-resources/models sudo docker run -p 10095:10095 -it --privileged=true \ -v $PWD/funasr-runtime-resources/models:/workspace/models \ registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.9 # 启动服务 cd FunASR/runtime nohup bash run_server_2pass.sh \ --download-model-dir /workspace/models \ --vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \ --model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx \ --online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx \ --punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \ --lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \ --itn-dir thuduj12/fst_itn_zh \ --hotword /workspace/models/hotwords.txt > log.txt 2>&1 & |
离线版本
https://github.com/alibaba-damo-academy/FunASR/blob/main/runtime/docs/SDK_advanced_guide_offline_zh.md
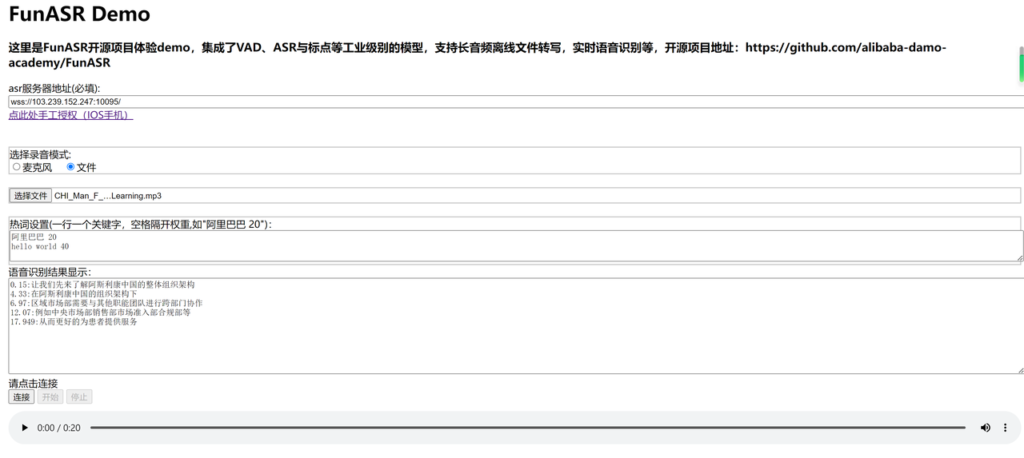
示例提供了前端页面,孙村服务器完成部署,本地打开html测试
asr服务器地址wss://103.239.152.247:10095/
Funasr微调
数据集格式需确定
https://github.com/alibaba-damo-academy/FunASR/blob/main/examples/industrial_data_pretraining/paraformer/finetune.sh
微调过程
https://github.com/alibaba-damo-academy/FunASR/wiki/%E5%BF%AB%E9%80%9F%E8%AE%AD%E7%BB%83#%E8%AE%AD%E7%BB%83%E8%BE%93%E5%85%A5%E5%8F%82%E6%95%B0%E4%BB%8B%E7%BB%8D
微调过程需要调用FunASR\examples\industrial_data_pretraining\paraformer目录下的finetune_from_local.sh脚本命令,同时需要对命令进行一些修改
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
workspace=`pwd` # 这里开始是定义了一个保存模型的目录,同事从modelscope上下载指定目录,我们也可以和原来的代码一样重新下载 local_path_root=${workspace}/modelscope_models mkdir -p ${local_path_root} local_path=${local_path_root}/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch git clone https://www.modelscope.cn/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch.git ${local_path} # 也可以用我们之前就下载好的目录直接定义local_path,指向我们保存模型的目录,例如 local_path=/home/inspur/hmx/Funasr/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch export CUDA_VISIBLE_DEVICES="0,1" gpu_num=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}') data_dir="/Users/zhifu/funasr1.0/data/list" # 这里需要将微调所需的数据目录修改成我们存储的数据目录 train_data="${data_dir}/train.jsonl" val_data="${data_dir}/val.jsonl" tokens="${local_path}/tokens.json" cmvn_file="${local_path}/am.mvn" output_dir="/Users/zhifu/exp" # 需要将这里的日志输出目录修改成指定目录 |
数据格式确认:
微调所需的数据放在脚本命令中定义的data_dir目录中,主要是准备好训练集和测试集的jsonl文件,jsonl文件可以使用funasr中的python代码,通过txt和scp文件生成,
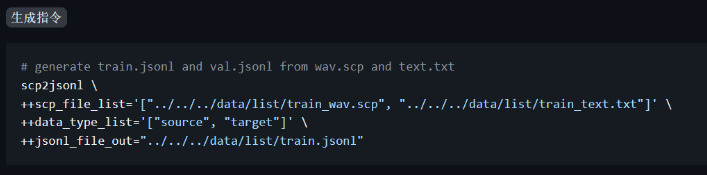
txt和scp的文件内容如下
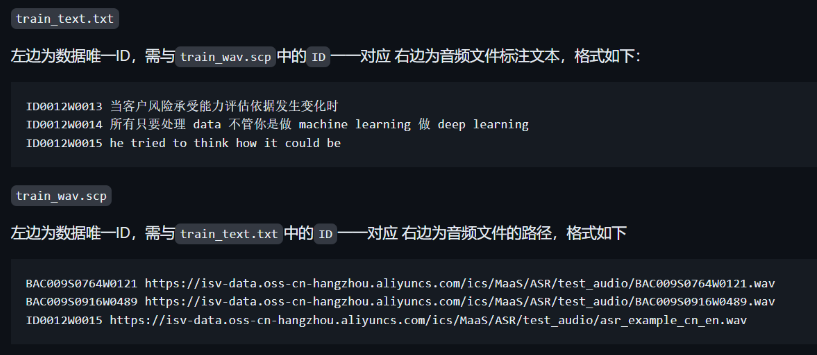
生成jsonl内容如下
|
1 2 3 |
{"key": "ID0012W0013", "prompt": "<ASR>", "source": "/Users/zhifu/funasr_github/test_local/aishell2_dev_ios/wav/D0012/ID0012W0013.wav", "target": "当客户风险承受能力评估依据发生变化时", "source_len": 454, "target_len": 19} {"key":"ID0012W0014", "prompt": "<ASR>", "source": "/Users/zhifu/funasr_github/test_local/aishell2_dev_ios/wav/D0012/ID0012W0014.wav", "target": "杨涛不得不将工厂关掉", "source_len": 211, "target_len": 11} |
Paddle Speech
代码库维护较差,依赖包版本混乱,容易出现bug
|
1 2 3 4 5 6 7 8 |
# https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/README_cn.md pip install PaddlePaddle==2.4.2 -i https://mirror.baidu.com/pypi/simple pip install pytest-runner -i https://pypi.tuna.tsinghua.edu.cn/simple pip install paddlespeech==1.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple # numpy版本冲突 重装 # pip install numpy==1.22.4 -i https://pypi.tuna.tsinghua.edu.cn/simple # pip install paddlenlp==2.5.2 -i https://pypi.tuna.tsinghua.edu.cn/simple |
