Pytorch官方给出了调用FFmpeg的示例,前提是ffmpeg必须是编译动态库。
一开始使用静态构建无法调用(
https://stackoverflow.com/questions/77479851/torchaudio-cant-find-ffmpeg https://stackoverflow.com/questions/76155851/diart-torchaudio-on-windows-x64-results-in-torchaudio-error-importerror-ffmp
https://zhuanlan.zhihu.com/p/629369210)
官方文档
https://pytorch.ac.cn/audio/stable/build.ffmpeg.html中文
https://pytorch.org/audio/stable/build.ffmpeg.html
|
1 2 3 4 5 6 7 8 9 10 |
# 查看解码器是否包含h264_cuvid ffprobe -hide_banner -decoders | sls h264 # 查看编码器是否包含h264_nvenc ffmpeg -hide_banner -encoders | sls 264 # 测试 ffmpeg -hide_banner -y -vsync 0 -hwaccel cuvid -hwaccel_output_format cuda -c:v h264_cuvid -resize 360x240 -i .\input.mp4 -c:a copy -c:v h264_nvenc -b:v 5M test.mp4 # 安装pytorch python3.8 pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121 # 调用报错 https://stackoverflow.com/questions/77479851/torchaudio-cant-find-ffmpeg 必须动态构建ffmpeg |
torchaudio测试输出编解码器与GPU
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
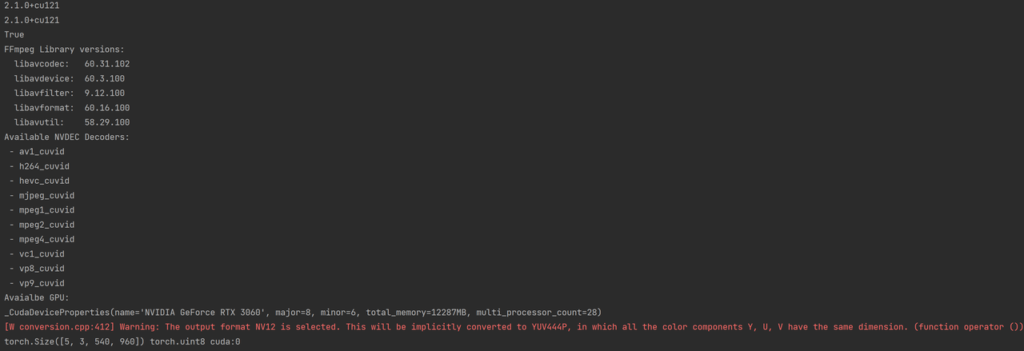
import torch import torchaudio print(torch.__version__) print(torchaudio.__version__) print(torch.cuda.is_available()) # import matplotlib.pyplot as plt from torchaudio.io import StreamReader from torchaudio.utils import ffmpeg_utils print("FFmpeg Library versions:") for k, ver in ffmpeg_utils.get_versions().items(): print(f" {k}:\t{'.'.join(str(v) for v in ver)}") print("Available NVDEC Decoders:") for k in ffmpeg_utils.get_video_decoders().keys(): if "cuvid" in k: print(f" - {k}") print("Avaialbe GPU:") print(torch.cuda.get_device_properties(0)) src = torchaudio.utils.download_asset( "tutorial-assets/stream-api/NASAs_Most_Scientifically_Complex_Space_Observatory_Requires_Precision-MP4_small.mp4" ) # cpu # s = StreamReader(src) # s.add_video_stream(5, decoder="h264_cuvid") # s.fill_buffer() # (video,) = s.pop_chunks() # print(video.shape, video.dtype) # print(video.device) # 解码至GPU s = StreamReader(src) s.add_video_stream(5, decoder="h264_cuvid", decoder_option={"gpu": "0"}, hw_accel="cuda:0") s.fill_buffer() (video,) = s.pop_chunks() print(video.shape, video.dtype, video.device) |
输出
https://pytorch.org/audio/stable/tutorials/streamreader_basic_tutorial.html
https://pytorch.org/audio/stable/tutorials/streamreader_advanced_tutorial.html
