Hadoop生态系统是一个很庞大的概念,hadoop是其中最重要最基础的一个部分,生态系统中每一子系统只解决某一个特定的问题域(甚至可能更窄),不是统一型的全能系统,而是小而精的多个小系统组合。
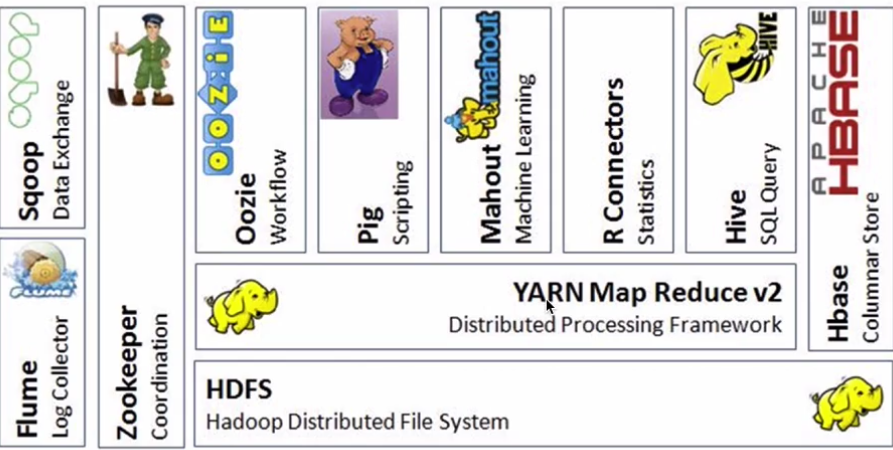
HDFS:分布式文件系统
Yarn:分布式资源管理器
Mapreduce:分布式计算模型,用以进行大数据量的计算
Hbase : 海量数据中的查询,相当于分布式文件系统中的数据库
Hive:数据仓库
R:数据分析
Mahout:机器学习库 已经很少使用
pig:脚本语言,跟Hive类似
Oozie:工作流引擎,管理作业执行顺序
Zookeeper:解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等
Flume:日志收集框架
Sqoop:数据交换框架,例如:关系型数据库与HDFS之间的数据交换
Spark: 基于内存的分布式的计算框架
- spark core
- spark sql
- spark streaming 准实时 不算是一个标准的流式计算
- spark ML spark MLlib
Kafka: 消息队列
Storm: 分布式的流式计算框架 python操作storm
Flink: 分布式的流式计算框架
