TensorRT解析难点
第⼆届TensorRT 加速 AI 推理⽐赛,利⽤ TensorRT 加速 ASR 模型 WeNet。比赛完成,简单总结下。
ONNX导入TensorRT通常会预见以下几个问题。
1. ONNX模型转化验证
Polygraphy工具可用于验证ONNX模型是否被TRT原生支持。若支持,则可用命令行直接转换模型;若不支持,则生成不支持的部分(ONNX格式),可通过Netron查看具体为哪些节点。
|
1 2 3 4 5 6 7 8 9 10 |
# 确认 TensorRT 是否完全原生支持该 .onnx polygraphy inspect capability model.onnx # 输出信息:[I] Graph is fully supported by TensorRT; Will not generate subgraphs. # 生成一个含有 TensorRT 不原生支持的 .onnx,再次用 inspect capability 来确认 python getOnnxModel-NonZero.py polygraphy inspect capability model-NonZero.onnx > result-NonZero.txt # 产生目录 .results,包含网络分析信息和支持的子图(.onnx)、不支持的子图(.onnx) |
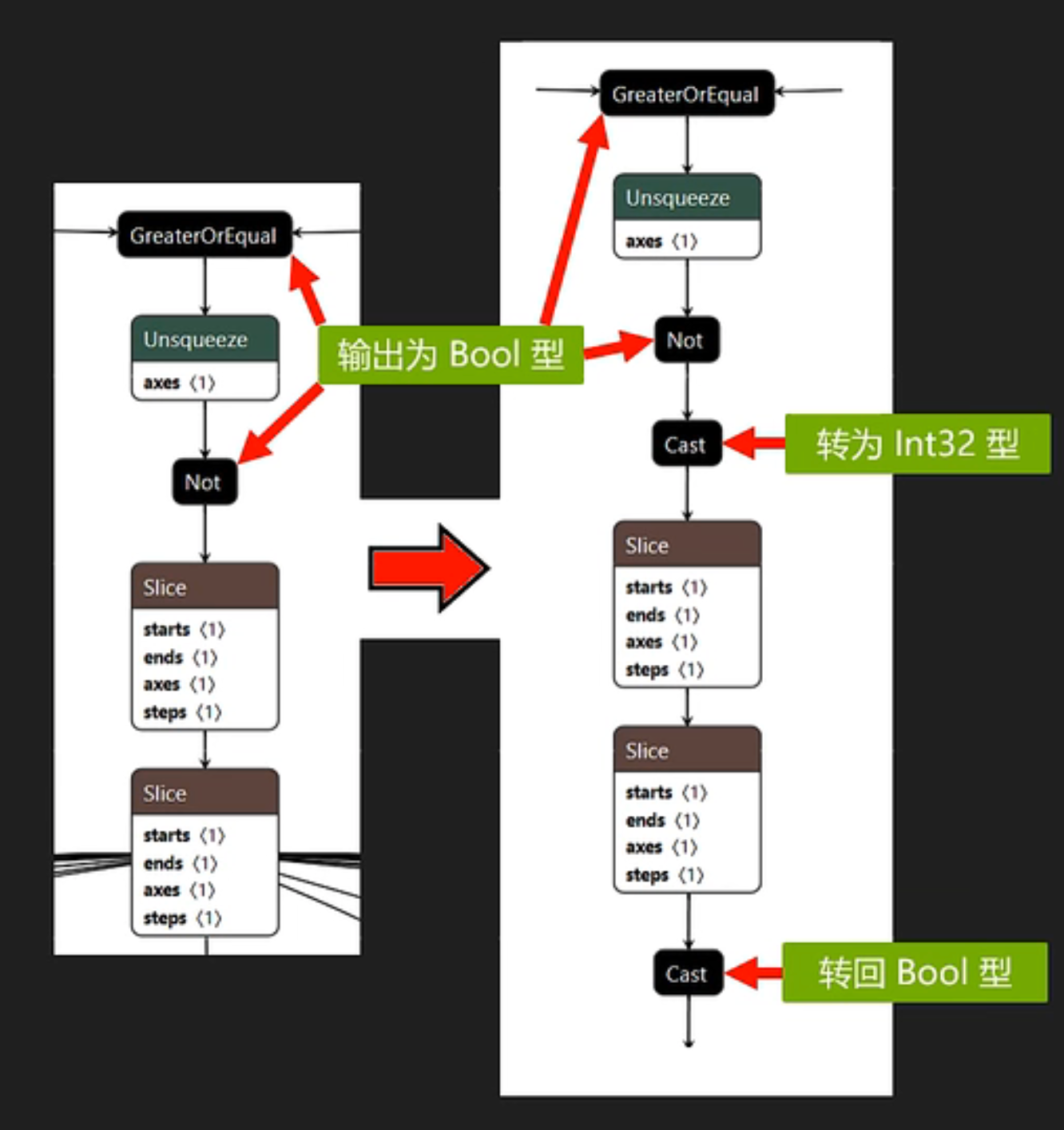
2. TRT不支持的算子
对于TRT不能解析的算子,一般可以通过功能相同的其他算子或者算子组合来替代。常用工具为Onnx-Graphsurgeon。该工具支持修改ONNX模型中的节点,如删除、替换、增加等。例如Wenet模型中encoder部分,某个Slice节点不能接收布尔类型输入输出,解决方法就是在该节点前后加入Cast节点,将布尔张量转为Int32类型。
3. 精度切换与混合精度
要实现更快的推理速度常见方式是将精度降为Fp16甚至int8。但往往降低精度,会导致最终输出误差超过可接受范围。此时可通过polygraphy逐层对比ONNX与TRT误差,找出误差较大的节点,在TensorRT Api中将该节点调回Fp32。
|
1 2 3 4 5 6 7 |
for i in range(network.num_layers): layer = network.get_layer(i) print(f'Network Layer {i}: {layer.name}, {layer.type}, {layer.precision}, is_set: {layer.precision_is_set}') if layer.name == 'Conv_37': layer.precision = trt.float32 config.flags = 1 << int(trt.BuilderFlag.STRICT_TYPES) |
当然,这是个折中的方法,终极解决方式还是用Plugin进行优化。
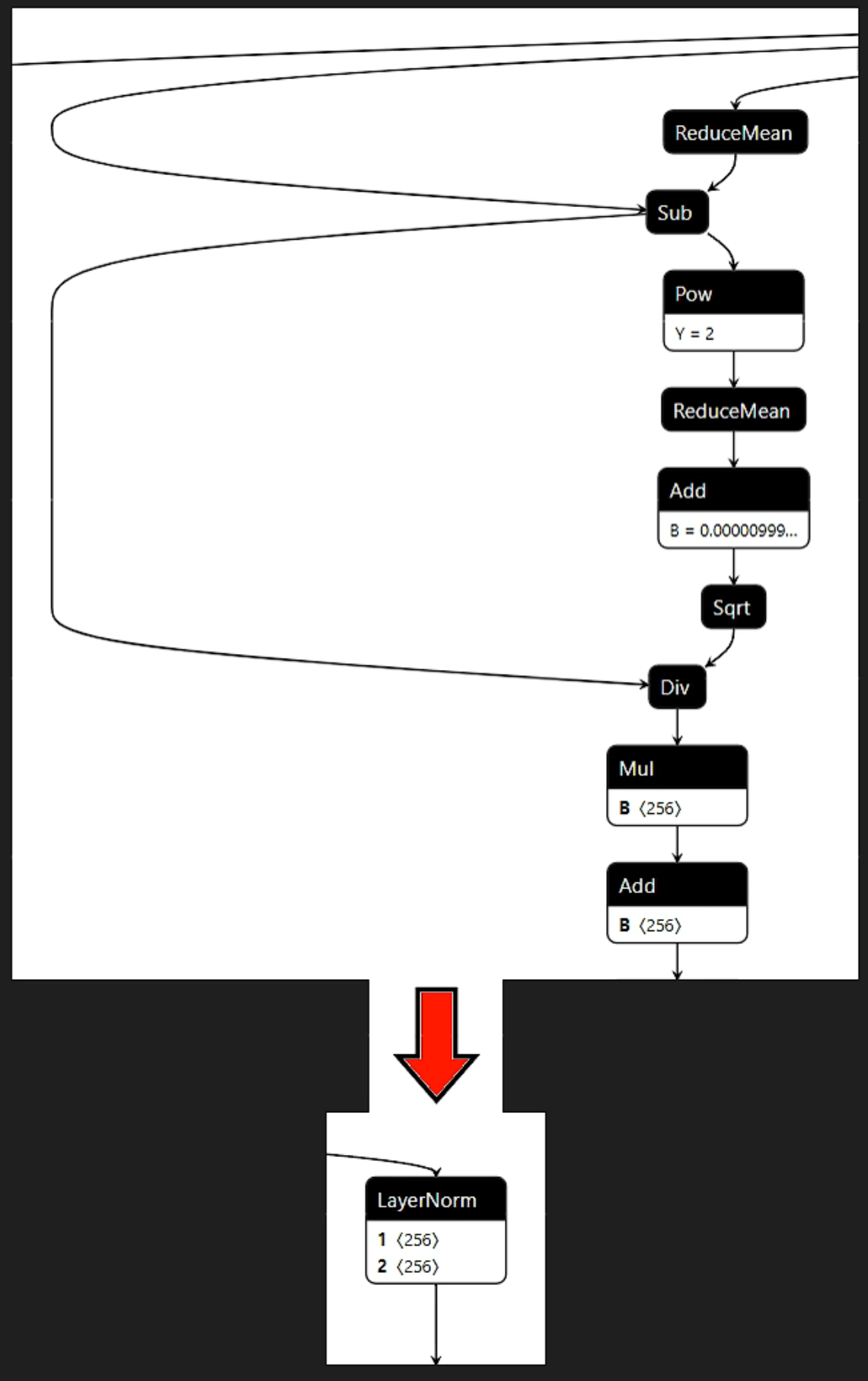
4. C++ Plugin性能优化
常见Plugin使用场景为:模型中频繁出现的算子模块,可以替换为性能更优的Plugin。例如Wenet中LayerNorm在Onnx中为多个算子的组合,用Onnx-Graphsurgeon将这些节点合并为一个LayerNorm节点。同时,书写Plugin,通过Cuda核函数实现LayerNorm的计算逻辑。在Onnx转TRT的过程中,TRT会自动寻找与LayerNorm的同名Plugin进行解析。